Reading data with coffea NanoEvents#
This is a rendered copy of nanoevents.ipynb. You can optionally run it interactively on binder at this link
NanoEvents is a Coffea utility to wrap flat nTuple structures (such as the CMS NanoAOD format) into a single awkward array with appropriate object methods (such as Lorentz vector methods$^*$), cross references, and nested objects, all accessed in delayed$^\dagger$ mode from the source ROOT TTree via uproot. The interpretation of the TTree data is configurable via schema objects, which are community-supplied for various source file types. These schema objects allow a richer interpretation of the file contents than the uproot methods. Currently available schemas include:
BaseSchema, which provides a simple representation of the input TTree, where each branch is available verbatim asevents.branch_name. Any branches that uproot supports at “full speed” (i.e. that are fully split and either flat or single-jagged) can be read by this schema;NanoAODSchema, which is optimized to provide all methods and cross-references in CMS NanoAOD format;PFNanoAODSchema, which builds a double-jagged particle flow candidate colllectionevents.jet.constituentsfrom compatible PFNanoAOD input files;TreeMakerSchemawhich is designed to read TTrees made by TreeMaker, an alternative CMS nTuplization format;PHYSLITESchema, for the ATLAS DAOD_PHYSLITE derivation, a compact centrally-produced data format similar to CMS NanoAOD; andDelphesSchema, for reading Delphes fast simulation nTuples.
We welcome contributions for new schemas, and can assist with the design of them.
$^*$ Vector methods are currently made possible via the coffea vector methods mixin class structure. In a future version of coffea, they will instead be provided by the dedicated scikit-hep vector library, which provides a more rich feature set. The coffea vector methods predate the release of the vector library.
$^\dagger$ delayed access refers to only fetching the needed data from the (possibly remote) file when you’re ready to compute the entire set of outputs. Until then, a minimal amount of metadata is used to trace the operations to eventually be performed (frequently called “lazily” “booking” operations in RDataFrame’s approach to this)
In this demo, we will use NanoEvents to read a small CMS NanoAOD sample. The events object can be instantiated as follows:
import awkward as ak
from coffea.nanoevents import NanoEventsFactory, NanoAODSchema
NanoAODSchema.warn_missing_crossrefs = False
fname = "coffea/tests/samples/nano_dy.root"
access_log = []
events = NanoEventsFactory.from_root(
{fname: "Events"},
schemaclass=NanoAODSchema,
metadata={"dataset": "DYJets"},
mode="eager",
access_log=access_log,
).events()
In the factory constructor, we also pass the desired schema version (the latest version of NanoAOD can be built with schemaclass=NanoAODSchema) for this file and some extra metadata that we can later access with events.metadata. In a later example, we will show how to set up this metadata in coffea processors where the events object is pre-created for you. Consider looking at the from_root class method to see all optional arguments.
The events object is an awkward array, which at its top level is a record array with one record for each “collection”, where a collection is a grouping of fields (TBranches) based on the naming conventions of NanoAODSchema. For example, in the file we opened, the branches:
Generator_binvar
Generator_scalePDF
Generator_weight
Generator_x1
Generator_x2
Generator_xpdf1
Generator_xpdf2
Generator_id1
Generator_id2
are grouped into one sub-record named Generator which can be accessed using either getitem or getattr syntax, i.e. events["Generator"] or events.Generator. e.g.
events.Generator.id1
[1,
-1,
-1,
21,
21,
4,
2,
-2,
2,
1,
...,
1,
-2,
2,
1,
2,
-2,
-1,
2,
1]
-----
backend: cpu
nbytes: 160 B
type: 40 * int32[parameters={"__doc__": "id of first parton", "typename": "int32_t"}]# all names can be listed with:
events.Generator.fields
['binvar', 'scalePDF', 'weight', 'x1', 'x2', 'xpdf1', 'xpdf2', 'id1', 'id2']
In CMS NanoAOD, each TBranch has a self-documenting help string embedded in the title field, which is carried into the NanoEvents, e.g. executing the following cell should produce a help pop-up:
Type: Array
String form: [1, -1, -1, 21, 21, 4, 2, -2, 2, 1, 3, 1, ... -1, -1, 1, -2, 2, 1, 2, -2, -1, 2, 1]
Length: 40
File: ~/src/awkward-1.0/awkward1/highlevel.py
Docstring: id of first parton
Class docstring: ...
where the Docstring shows information about the content of this array.
events.Generator.id1?
Type: Array
String form: [1, -1, -1, 21, 21, 4, 2, -2, 2, 1, 3, ..., -1, 1, -2, 2, 1, 2, -2, -1, 2, 1]
Length: 40
File: ~/Dropbox/work/pyhep_dev/awkward/src/awkward/highlevel.py
Docstring: id of first parton
Class docstring:
Args:
data (#ak.contents.Content, #ak.Array, `np.ndarray`, `cp.ndarray`, `pyarrow.*`, str, dict, or iterable):
Data to wrap or convert into an array.
- If a NumPy array, the regularity of its dimensions is preserved
and the data are viewed, not copied.
- CuPy arrays are treated the same way as NumPy arrays except that
they default to `backend="cuda"`, rather than `backend="cpu"`.
- If a pyarrow object, calls #ak.from_arrow, preserving as much
metadata as possible, usually zero-copy.
- If a dict of str → columns, combines the columns into an
array of records (like Pandas's DataFrame constructor).
- If a string, the data are assumed to be JSON.
- If an iterable, calls #ak.from_iter, which assumes all dimensions
have irregular lengths.
behavior (None or dict): Custom #ak.behavior for this Array only.
with_name (None or str): Gives tuples and records a name that can be
used to override their behavior (see below).
check_valid (bool): If True, verify that the #layout is valid.
backend (None, `"cpu"`, `"jax"`, `"cuda"`): If `"cpu"`, the Array will be placed in
main memory for use with other `"cpu"` Arrays and Records; if `"cuda"`,
the Array will be placed in GPU global memory using CUDA; if `"jax"`, the structure
is copied to the CPU for use with JAX. if None, the `data` are left untouched.
High-level array that can contain data of any type.
For most users, this is the only class in Awkward Array that matters: it
is the entry point for data analysis with an emphasis on usability. It
intentionally has a minimum of methods, preferring standalone functions
like
ak.num(array1)
ak.combinations(array1)
ak.cartesian([array1, array2])
ak.zip({"x": array1, "y": array2, "z": array3})
instead of bound methods like
array1.num()
array1.combinations()
array1.cartesian([array2, array3])
array1.zip(...) # ?
because its namespace is valuable for domain-specific parameters and
functionality. For example, if records contain a field named `"num"`,
they can be accessed as
array1.num
instead of
array1["num"]
without any confusion or interference from #ak.num. The same is true
for domain-specific methods that have been attached to the data. For
instance, an analysis of mailing addresses might have a function that
computes zip codes, which can be attached to the data with a method
like
latlon.zip()
without any confusion or interference from #ak.zip. Custom methods like
this can be added with #ak.behavior, and so the namespace of Array
attributes must be kept clear for such applications.
See also #ak.Record.
Interfaces to other libraries
=============================
NumPy
*****
When NumPy
[universal functions](https://docs.scipy.org/doc/numpy/reference/ufuncs.html)
(ufuncs) are applied to an ak.Array, they are passed through the Awkward
data structure, applied to the numerical data at its leaves, and the output
maintains the original structure.
For example,
>>> array = ak.Array([[1, 4, 9], [], [16, 25]])
>>> np.sqrt(array)
<Array [[1, 2, 3], [], [4, 5]] type='3 * var * float64'>
See also #ak.Array.__array_ufunc__.
Some NumPy functions other than ufuncs are also handled properly in
NumPy >= 1.17 (see
[NEP 18](https://numpy.org/neps/nep-0018-array-function-protocol.html))
and if an Awkward override exists. That is,
np.concatenate
can be used on an Awkward Array because
ak.concatenate
exists.
Pandas
******
Ragged arrays (list type) can be converted into Pandas
[MultiIndex](https://pandas.pydata.org/pandas-docs/stable/user_guide/advanced.html)
rows and nested records can be converted into MultiIndex columns. If the
Awkward Array has only one "branch" of nested lists (i.e. different record
fields do not have different-length lists, but a single chain of lists-of-lists
is okay), then it can be losslessly converted into a single DataFrame.
Otherwise, multiple DataFrames are needed, though they can be merged (with a
loss of information).
The #ak.to_dataframe function performs this conversion; if `how=None`, it
returns a list of DataFrames; otherwise, `how` is passed to `pd.merge` when
merging the resultant DataFrames.
Numba
*****
Arrays can be used in [Numba](https://numba.pydata.org/): they can be
passed as arguments to a Numba-compiled function or returned as return
values. The only limitation is that Awkward Arrays cannot be *created*
inside the Numba-compiled function; to make outputs, consider
#ak.ArrayBuilder.
Arrow
*****
Arrays are convertible to and from [Apache Arrow](https://arrow.apache.org/),
a standard for representing nested data structures in columnar arrays.
See #ak.to_arrow and #ak.from_arrow.
JAX
********
Derivatives of a calculation on an #ak.Array (s) can be calculated with
[JAX](https://github.com/google/jax#readme), but only if the array
functions in `ak` / `numpy` are used, not the functions in the `jax`
library directly (apart from e.g. `jax.grad`).
Like NumPy ufuncs, the function and its derivatives are evaluated on the
numeric leaves of the data structure, maintaining structure in the output.
Based on a collection’s name or contents, some collections acquire additional methods, which are extra features exposed by the code in the mixin classes of the coffea.nanoevents.methods modules. For example, although events.GenJet has the fields:
events.GenJet.fields
['eta', 'mass', 'phi', 'pt', 'partonFlavour', 'hadronFlavour']
we can access additional attributes associated to each generated jet by virtue of the fact that they can be interpreted as Lorentz vectors:
events.GenJet.energy
[[217, 670, 258],
[34.5, 98.3, 1.16e+03, 38.1, 20.4, 29.7],
[306, 62.8, 74.1, 769, 11.2],
[170, 117, 29.3, 45.9],
[101, 117, 129, 15.6],
[63.1, 37.2, 33.7, 36.2],
[303, 50.5, 1.29e+03, 278],
[615, 282, 2.11e+03],
[195, 47.6],
[95, 44.6, 223, 318, 30, 108, 62.9],
...,
[41.6, 36.7, 78.9, 13],
[1.51e+03, 1.23e+03],
[152, 160, 777, 27.1, 346, 65.1, 37.9, 27.2, 16.3],
[35.4, 20.4],
[20.1, 16.2],
[34],
[553, 283],
[771, 452, 16],
[76.9]]
----------------------------------------------------
backend: cpu
nbytes: 836 B
type: 40 * var * float32[parameters={"typename": "float[]"}]We can call more complex methods, like computing the distance $\Delta R = \sqrt{\Delta \eta^2 + \Delta \phi ^2}$ between two LorentzVector objects:
# find distance between leading jet and all electrons in each event
dr = events.Jet[:, 0].delta_r(events.Electron)
dr
[[],
[3.13],
[3.45, 2.18],
[1.58, 3.76],
[],
[0.053],
[0.0748],
[],
[],
[1.82],
...,
[0.00115],
[],
[0.0149],
[],
[0.0308],
[],
[0.0858],
[],
[]]
--------------
backend: cpu
nbytes: 428 B
type: 40 * var * float32[parameters={"typename": "float[]"}]# find minimum distance
drmin = ak.min(dr, axis=1)
drmin
[None, 3.13, 2.18, 1.58, None, 0.053, 0.0748, None, None, 1.82, ..., 0.00115, None, 0.0149, None, 0.0308, None, 0.0858, None, None] --------- backend: cpu nbytes: 200 B type: 40 * ?float32
# a convenience method for this operation on all jets is available
events.Jet.nearest(events.Electron)
[[None, None, None, None, None],
[Electron, Electron, ..., Electron, Electron],
[Electron, Electron, ..., Electron],
[Electron, Electron, Electron],
[None, None, None, None, None],
[Electron, Electron, ..., Electron, Electron],
[Electron, Electron, Electron, Electron],
[None, None, None, None],
[None],
[Electron, Electron, ..., Electron],
...,
[Electron, Electron],
[None, None, None, None],
[Electron, Electron, ..., Electron],
[None, None, None],
[Electron, Electron],
[None, None, None],
[{deltaEtaSC: -0.00986, dr03EcalRecHitSumEt: 0, ...}],
[None, None, None, None, None, None],
[None, None]]
-------------------------------------------------------
backend: cpu
nbytes: 7.1 kB
type: 40 * var * ?Electron[
deltaEtaSC: float32[parameters={"__doc__": "delta eta (SC,ele) with sign", "typename": "float[]"}],
dr03EcalRecHitSumEt: float32[parameters={"__doc__": "Non-PF Ecal isolation within a delta R cone of 0.3 with electron pt > 35 GeV", "typename": "float[]"}],
dr03HcalDepth1TowerSumEt: float32[parameters={"__doc__": "Non-PF Hcal isolation within a delta R cone of 0.3 with electron pt > 35 GeV", "typename": "float[]"}],
dr03TkSumPt: float32[parameters={"__doc__": "Non-PF track isolation within a delta R cone of 0.3 with electron pt > 35 GeV", "typename": "float[]"}],
dr03TkSumPtHEEP: float32[parameters={"__doc__": "Non-PF track isolation within a delta R cone of 0.3 with electron pt > 35 GeV used in HEEP ID", "typename": "float[]"}],
dxy: float32[parameters={"__doc__": "dxy (with sign) wrt first PV, in cm", "typename": "float[]"}],
dxyErr: float32[parameters={"__doc__": "dxy uncertainty, in cm", "typename": "float[]"}],
dz: float32[parameters={"__doc__": "dz (with sign) wrt first PV, in cm", "typename": "float[]"}],
dzErr: float32[parameters={"__doc__": "dz uncertainty, in cm", "typename": "float[]"}],
eCorr: float32[parameters={"__doc__": "ratio of the calibrated energy/miniaod energy", "typename": "float[]"}],
...
parameters={"__doc__": "slimmedElectrons after basic selection (pt > 5 )", "collection_name": "Electron"}]The assignment of methods classes to collections is done inside the schema object during the initial creation of the array, governed by the awkward array’s __record__ parameter and the associated behavior. See ak.behavior for a more detailed explanation of array behaviors.
Additional methods provide convenience functions for interpreting some branches, e.g. CMS NanoAOD packs several jet identification flag bits into a single integer, jetId. By implementing the bit-twiddling in the Jet mixin, the analysis code becomes more clear:
print(events.Jet.jetId)
print(events.Jet.isTight)
[[6, 6, 6, 6, 6], [6, 2, 6, 6, 6, 6, 6, 0], ..., [6, 6, 0, ..., 6, 6], [6, 6]]
[[True, True, True, True, True], [True, True, ..., False], ..., [True, True]]
We can also define convenience functions to unpack and apply some mask to a set of flags, e.g. for generated particles:
print(f"Raw status flags: {events.GenPart.statusFlags}")
events.GenPart.hasFlags(["isPrompt", "isLastCopy"])
Raw status flags: [[10625, 27009, 4481, 22913, 257, ..., 13884, 13884, 13884, 12876, 12876], ...]
[[True, True, False, False, False, ..., False, False, False, False, False],
[True, True, False, False, False, False, ..., True, True, True, True, False],
[False, True, False, False, False, ..., False, False, False, False, False],
[True, False, False, False, False, ..., False, False, False, False, False],
[True, False, False, False, False, False, ..., True, True, True, False, False],
[True, True, False, False, False, ..., False, False, False, False, False],
[False, False, False, False, False, ..., True, False, False, False, False],
[True, True, False, False, False, True, ..., True, True, False, False, False],
[True, True, False, False, False, ..., False, False, False, False, False],
[True, True, False, False, False, ..., False, False, False, False, False],
...,
[True, True, False, False, False, ..., False, False, False, False, False],
[True, True, False, False, False, True, ..., True, False, True, True, True],
[False, False, False, False, False, ..., False, False, False, False, False],
[True, True, False, False, False, ..., False, False, False, False, False],
[True, True, False, False, False, ..., False, False, False, False, False],
[True, True, False, False, False, ..., False, False, False, False, False],
[True, True, False, True, True, True],
[True, True, False, False, True, False, False, True, True, True],
[True, True, False, False, False, ..., False, False, False, False, False]]
--------------------------------------------------------------------------------
backend: cpu
nbytes: 1.4 kB
type: 40 * var * bool[parameters={"__doc__": "gen status flags stored bitwise, bits are: 0 : isPrompt, 1 : isDecayedLeptonHadron, 2 : isTauDecayProduct, 3 : isPromptTauDecayProduct, 4 : isDirectTauDecayProduct, 5 : isDirectPromptTauDecayProduct, 6 : isDirectHadronDecayProduct, 7 : isHardProcess, 8 : fromHardProcess, 9 : isHardProcessTauDecayProduct, 10 : isDirectHardProcessTauDecayProduct, 11 : fromHardProcessBeforeFSR, 12 : isFirstCopy, 13 : isLastCopy, 14 : isLastCopyBeforeFSR, ", "typename": "int32_t[]"}]CMS NanoAOD also contains pre-computed cross-references for some types of collections. For example, there is a TBranch Electron_genPartIdx which indexes the GenPart collection per event to give the matched generated particle, and -1 if no match is found. NanoEvents transforms these indices into an awkward indexed array pointing to the collection, so that one can directly access the matched particle using getattr syntax:
events.Electron.matched_gen.pdgId
[[],
[-11],
[-11, 11],
[22, None],
[],
[None],
[None],
[],
[],
[11],
...,
[11],
[],
[11],
[],
[-11],
[],
[None],
[],
[]]
------------
backend: cpu
nbytes: 4.8 kB
type: 40 * var * ?int32[parameters={"__doc__": "PDG id", "typename": "int32_t[]"}]events.Muon[ak.num(events.Muon) > 0].matched_jet.pt
[[84.4, 29.4],
[31.1],
[53.4, 81.9],
[29.2],
[17.5],
[65.9, 47.8],
[58.5, 44.7],
[50.2, 45.2],
[33.3, 25.9],
[None],
[26.1],
[25.8]]
--------------
backend: cpu
nbytes: 1,000 B
type: 12 * var * ?float32[parameters={"__doc__": "pt", "typename": "float[]"}]For generated particles, the parent index is similarly mapped:
events.GenPart.parent.pdgId
[[None, None, 1, 1, 23, 23, 23, 23, ..., 15, -15, -15, -15, -15, -15, 111, 111],
[None, None, -1, 23, 23, 23, 23, ..., -11, None, None, None, None, None, 433],
[None, None, -1, -1, 23, 23, 23, 23, ..., -423, -1, -1, -421, -421, 111, 111],
[None, None, 21, 21, 23, -1, 23, 23, ..., -15, -15, -15, -15, -15, 111, 111],
[None, None, 21, 21, 23, 23, 23, 23, ..., 13, 13, -13, 1, None, None, 2, 2],
[None, None, 4, 23, 23, 23, 23, 23, ..., -15, -15, -15, 15, 15, 15, 423, 311],
[None, None, 2, 2, 2, 23, 23, 2, 23, ..., -13, 13, 2, 2, 2, 2, 111, 111, 111],
[None, None, -2, -2, 23, 21, 21, 23, 23, ..., 21, 21, 21, 21, None, 423, 2, 2],
[None, None, 2, 23, 23, 23, 23, 23, ..., -15, -15, -15, -15, 111, 111, 311],
[None, None, 1, 1, 1, 23, 21, 23, 23, 23, ..., -411, 21, 21, 1, 1, 1, 1, 3, 3],
...,
[None, None, 1, 23, 23, 23, 23, 23, ..., -15, -15, -15, -15, 1, 1, 111, 111],
[None, None, -2, 23, 23, 23, 23, 23, 13, 13, -13, -13, -13, 13],
[None, None, 2, 2, 2, 23, 2, 23, ..., None, -413, 413, 413, 2, 2, -421, -421],
[None, None, 1, 23, 23, 23, 23, 23, ..., -15, 15, 15, 15, -15, -15, -15, -15],
[None, None, 2, 2, 23, 23, 21, 23, ..., 15, 15, 15, -15, -15, -15, 111, 111],
[None, None, -2, 23, 23, None, 23, 23, ..., -15, -15, -15, 423, 4, 4, 3, 3],
[None, None, -1, 23, 23, 23],
[None, None, 2, 23, 23, 23, 23, -11, -11, 11],
[None, None, 1, 1, 23, 23, 23, 23, ..., -15, -15, -15, 111, 111, 111, 111]]
--------------------------------------------------------------------------------
backend: cpu
nbytes: 13.1 kB
type: 40 * var * ?int32[parameters={"__doc__": "PDG id", "typename": "int32_t[]"}]In addition, using the parent index, a helper method computes the inverse mapping, namely, children. As such, one can find particle siblings with:
events.GenPart.parent.children.pdgId
# notice this is a doubly-jagged array
[[None, None, [23, 21], ..., [-16, 111, ..., 211, -211], [22, 22], [22, 22]],
[None, None, [23], [23], [23], [23], ..., None, None, None, None, None, [431]],
[None, None, [23, -1], [23, -1], [23], ..., [13, -14], [13, -14], [22], [22]],
[None, None, [23, -1], ..., [-16, 111, ..., 211, -211], [22, 22], [22, 22]],
[None, None, [23, 1], [23, 1], [23], ..., None, None, [11, -11], [11, -11]],
[None, None, [23], [23], ..., [16, 13, -14], [16, 13, -14], [421], [310]],
[None, None, [23, 2, 2], [23, 2, 2], ..., [...], [22], [11, -11], [11, -11]],
[None, None, [23, 21], [23, 21], [23], ..., None, [421], [11, -11], [11, -11]],
[None, None, [23], [23], ..., [-16, 111, ..., 311], [22, 22], [22, 22], [310]],
[None, None, [23, 21, 21], [23, ...], ..., [11, -11], [11, -11], [11, -11]],
...,
[None, None, [23], [23], [23], ..., [11, -11], [11, -11], [22, 22], [22, 22]],
[None, None, [23], [23], [23], ..., [...], [-13], [-13, 22], [-13, 22], [13]],
[None, None, [23, 2, 21], ..., [2, 21, ..., 11, -11], [13, -14], [13, -14]],
[None, None, [23], ..., [...], [-16, 211, 211, -211], [-16, 211, 211, -211]],
[None, None, [23, 21], [23, 21], ..., [-16, -11, 12], [22, 22], [22, 22]],
[None, None, [23], [23], ..., [423, -421, 11, -11], [11, -11], [11, -11]],
[None, None, [23], [23], [-13, 13], [-13, 13]],
[None, None, [23], [23], [23], ..., [-11, 11], [-11, 22], [-11, 22], [11]],
[None, None, [23, 21], [23, 21], ..., [22, ...], [22, 22], [22, 22], [22, 22]]]
--------------------------------------------------------------------------------
backend: cpu
nbytes: 39.9 kB
type: 40 * var * option[var * ?int32[parameters={"__doc__": "PDG id", "typename": "int32_t[]"}]]Since often one wants to shortcut repeated particles in a decay sequence, a helper method distinctParent is also available. Here we use it to find the parent particle ID for all prompt electrons:
events.GenPart[(abs(events.GenPart.pdgId) == 11) & events.GenPart.hasFlags(["isPrompt", "isLastCopy"])].distinctParent.pdgId
[[],
[23, 23],
[23, 23],
[],
[],
[],
[],
[23, 23],
[],
[23, 23],
...,
[],
[],
[23, 23],
[],
[],
[],
[],
[23, 23],
[]]
----------
backend: cpu
nbytes: 4.8 kB
type: 40 * var * ?int32[parameters={"__doc__": "PDG id", "typename": "int32_t[]"}]Events can be filtered like any other awkward array using boolean fancy-indexing
mmevents = events[ak.num(events.Muon) == 2]
zmm = mmevents.Muon[:, 0] + mmevents.Muon[:, 1]
zmm.mass
[94.6,
87.6,
88,
90.4,
89.1,
31.6]
------
backend: cpu
nbytes: 24 B
type: 6 * float32[parameters={"typename": "float[]"}]# a convenience method is available to sum vectors along an axis:
mmevents.Muon.sum(axis=1).mass
[94.6, 87.6, 88, 90.4, 89.1, 31.6] ------ backend: cpu nbytes: 24 B type: 6 * float32
As expected for this sample, most of the dimuon events have a pair invariant mass close to that of a Z boson. But what about the last event? Let’s take a look at the generator information:
print(mmevents[-1].Muon.matched_gen.pdgId)
print(mmevents[-1].Muon.matched_gen.hasFlags(["isPrompt"]))
[-13, 13]
[False, False]
So they are real generated muons, but they are not prompt (i.e. from the initial decay of a heavy resonance)
Let’s look at their parent particles:
mmevents[-1].Muon.matched_gen.parent.pdgId
[-15,
15]
-----
backend: cpu
nbytes: 4.3 kB
type: 2 * ?int32[parameters={"__doc__": "PDG id", "typename": "int32_t[]"}]aha! They are muons coming from tau lepton decays, and hence a fair amount of the Z mass is carried away by the neutrinos:
print(mmevents.Muon.matched_gen.sum().mass[-1])
print(mmevents.Muon.matched_gen.parent.sum().mass[-1])
31.265434
91.683304
One can assign new variables to the arrays, with some caveats:
Assignment must use setitem (
events["path", "to", "name"] = value)Assignment to a sliced
eventswon’t be accessible from the original variableNew variables are not visible from cross-references
mmevents["Electron", "myvariable"] = mmevents.Electron.pt + zmm.mass
mmevents.Electron.myvariable
[[],
[121],
[],
[],
[],
[]]
-------
backend: cpu
nbytes: 60 B
type: 6 * var * float32[parameters={"typename": "float[]"}]Virtual mode#
NanoEvents supports reading lazily in “virtual” mode. In that mode, branches will only be loaded from the root file when an explicit computation needs them. This is the default mode of operation of NanoEvents and we will be using this moving forward.
fname = "coffea/tests/samples/nano_dy.root"
access_log = []
events = NanoEventsFactory.from_root(
{fname: "Events"},
schemaclass=NanoAODSchema,
metadata={"dataset": "DYJets"},
mode="virtual",
access_log=access_log,
).events()
print(events.Jet.nearest(events.Electron))
print(access_log)
[[None, None, None, None, None], [Electron, Electron, ..., Electron], ..., [None, None]]
['nJet', 'nElectron', 'Jet_pt', 'Jet_phi', 'Jet_eta', 'Electron_pt', 'Electron_phi', 'Electron_eta']
events.Jet.jetId
[??,
??,
??,
??,
??,
??,
??,
??,
??,
??,
...,
??,
??,
??,
??,
??,
??,
??,
??,
??]
-----
backend: cpu
nbytes: 1.1 kB
type: 40 * var * int32[parameters={"__doc__": "Jet ID flags bit1 is loose (always false in 2017 since it does not exist), bit2 is tight, bit3 is tightLepVeto", "typename": "int32_t[]"}]events.Jet.isTight
[[True, True, True, True, True],
[True, True, True, True, True, True, True, False],
[True, True, True, True, True],
[False, True, True],
[True, True, True, True, True],
[True, False, True, True, True, True, True, True],
[True, False, True, True],
[True, True, True, True],
[True],
[False, True, True, True, True, True, True, True, True],
...,
[True, True],
[True, True, True, True],
[True, True, True, True, True, True, True, True, True],
[True, True, True],
[True, True],
[True, True, True],
[True],
[True, True, False, True, True, True],
[True, True]]
---------------------------------------------------------
backend: cpu
nbytes: 516 B
type: 40 * var * bool[parameters={"__doc__": "Jet ID flags bit1 is loose (always false in 2017 since it does not exist), bit2 is tight, bit3 is tightLepVeto", "typename": "int32_t[]"}]access_log
['nJet',
'nElectron',
'Jet_pt',
'Jet_phi',
'Jet_eta',
'Electron_pt',
'Electron_phi',
'Electron_eta',
'Jet_jetId']
events.Jet.jetId
[[6, 6, 6, 6, 6],
[6, 2, 6, 6, 6, 6, 6, 0],
[6, 2, 2, 6, 6],
[0, 6, 6],
[6, 2, 6, 6, 6],
[6, 0, 2, 6, 6, 6, 6, 6],
[6, 0, 6, 6],
[6, 6, 6, 6],
[6],
[0, 2, 6, 6, 6, 6, 6, 6, 6],
...,
[2, 6],
[6, 6, 6, 6],
[2, 6, 6, 6, 6, 6, 6, 6, 6],
[6, 6, 6],
[6, 6],
[6, 6, 6],
[6],
[6, 6, 0, 6, 6, 6],
[6, 6]]
-----------------------------
backend: cpu
nbytes: 1.1 kB
type: 40 * var * int32[parameters={"__doc__": "Jet ID flags bit1 is loose (always false in 2017 since it does not exist), bit2 is tight, bit3 is tightLepVeto", "typename": "int32_t[]"}]mmevents = events[ak.num(events.Muon) == 2]
zmm = mmevents.Muon[:, 0] + mmevents.Muon[:, 1]
zmm.mass
[94.6,
87.6,
88,
90.4,
89.1,
31.6]
------
backend: cpu
nbytes: 24 B
type: 6 * float32[parameters={"typename": "float[]"}]access_log
['nJet',
'nElectron',
'Jet_pt',
'Jet_phi',
'Jet_eta',
'Electron_pt',
'Electron_phi',
'Electron_eta',
'Jet_jetId',
'nMuon',
'Muon_pt',
'Muon_phi',
'Muon_eta',
'Muon_mass',
'Muon_charge']
The access_log keeps track of the branch we load in a time-ordered manner. Notice how after every cell above, only the branches that are actually required to evaluate that cell are loaded.
Dask mode#
Finally, NanoEvents supports “dask” mode. In that mode, the whole events object is a lazy dask-awkward (https://dask-awkward.readthedocs.io/en/stable/#) array. All the operations create a computational graph of “to be evaluated” steps that actually only run when compute gets called. Feel free to read about dask and dask.array too to understand general concepts of how it works.
import dask
fname = "coffea/tests/samples/nano_dy.root"
events = NanoEventsFactory.from_root(
{fname: "Events"},
schemaclass=NanoAODSchema,
metadata={"dataset": "DYJets"},
mode="dask",
).events()
events.Jet.nearest(events.Electron)
dask.awkward<firsts, type='## * var * ?Electron', npartitions=1>
a, b = dask.compute(events.Jet.jetId, events.Jet.isTight)
print(a)
print(b)
[[6, 6, 6, 6, 6], [6, 2, 6, 6, 6, 6, 6, 0], ..., [6, 6, 0, ..., 6, 6], [6, 6]]
[[True, True, True, True, True], [True, True, ..., False], ..., [True, True]]
mmevents = events[ak.num(events.Muon) == 2]
zmm = mmevents.Muon[:, 0] + mmevents.Muon[:, 1]
zmm_mass = zmm.mass
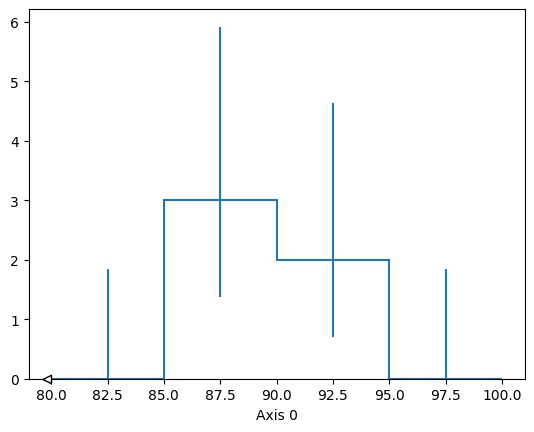
zmm_mass.visualize(rankdir="LR", optimize_graph=False)

from hist.dask import Hist
h = Hist.new.Reg(4, 80, 100).Double().fill(zmm_mass)
h.visualize(rankdir="LR", optimize_graph=False)

h.compute().plot()
[StairsArtists(stairs=<matplotlib.patches.StepPatch object at 0x148cad160>, errorbar=<ErrorbarContainer object of 3 artists>, legend_artist=<ErrorbarContainer object of 3 artists>)]